The Pilot-to-Production Gap
McKinsey's 2025 State of AI survey quantified what most AI vendors avoid discussing: 62% of enterprises are experimenting with agentic AI, but in no single business function does the share actually scaling exceed 10%. Deloitte's 2025 Emerging Technology Trends study breaks it down further: 38% are piloting, only 11% are in production.
This is not a model quality problem. The models work. The gap between pilots and production almost always traces back to one thing: the layer between your agents and your people was never properly designed.
“Most platforms treat the human-agent interface as an afterthought - shipping a generic chat UI and letting the customer figure out why adoption is stagnant six months post-launch.
This guide is the architecture documentation that should have come with your agentic AI platform.
What Is the Human-Agent Interface Layer?
The Human-Agent Interface Layer (HAIL) sits between your running agent system and every human who interacts with it - whether approving an action, monitoring performance, reviewing output, or providing mid-task input.
The contract shift: Traditional software has a simple contract: user initiates, system responds. Agentic AI breaks that contract. The agent acts; the human receives, reviews, and optionally intervenes. Designing for delegation instead of interaction is a fundamentally different problem.
Getting HAIL right requires deliberate choices across four dimensions:
Interface Format
What format the human sees output in - from dashboards to approval queues to conversational chat.
HITL Checkpoints
Where the agent pauses execution for human review, input, or approval before proceeding.
Observability
How you maintain end-to-end visibility into agent behavior, cost, latency, and decision quality.
Multi-Agent Routing
How you route across multi-agent systems without losing human oversight at critical junctures.
Match the Interface Format to the Decision Type
Before you write a single line of interface code, you need a decision framework. The wrong format kills adoption as reliably as a broken integration.
The two primary variables are decision frequency (how often does a human interact?) and consequence of error (what happens when the agent is wrong?). Plot your use case on that grid and the format selection follows.
Programmatic / M2M
Agent runs autonomously, outputs via webhooks and JSON. Humans see aggregate dashboards only.
Operational Dashboard
Agents run continuously; humans maintain situational awareness through monitoring rather than per-action review.
Approval Queue
Agent proposes an action, execution suspends until human approves, edits, or rejects with full context.
Conversational Chat
Natural language interaction for goal expression and iteration. Best when context is ambiguous.
Embedded Copilot
Agent embedded in existing tools - CRM sidebar, ERP suggestion panel. Minimizes adoption friction.
Structured Report
Agent runs long analysis and surfaces a curated summary. Designed for asynchronous consumption.
Key insight: Most production systems need multiple formats simultaneously. An accounts payable clerk gets an approval queue, their manager gets a dashboard, and the CFO gets a weekly digest. Same agent architecture, persona-specific interfaces.
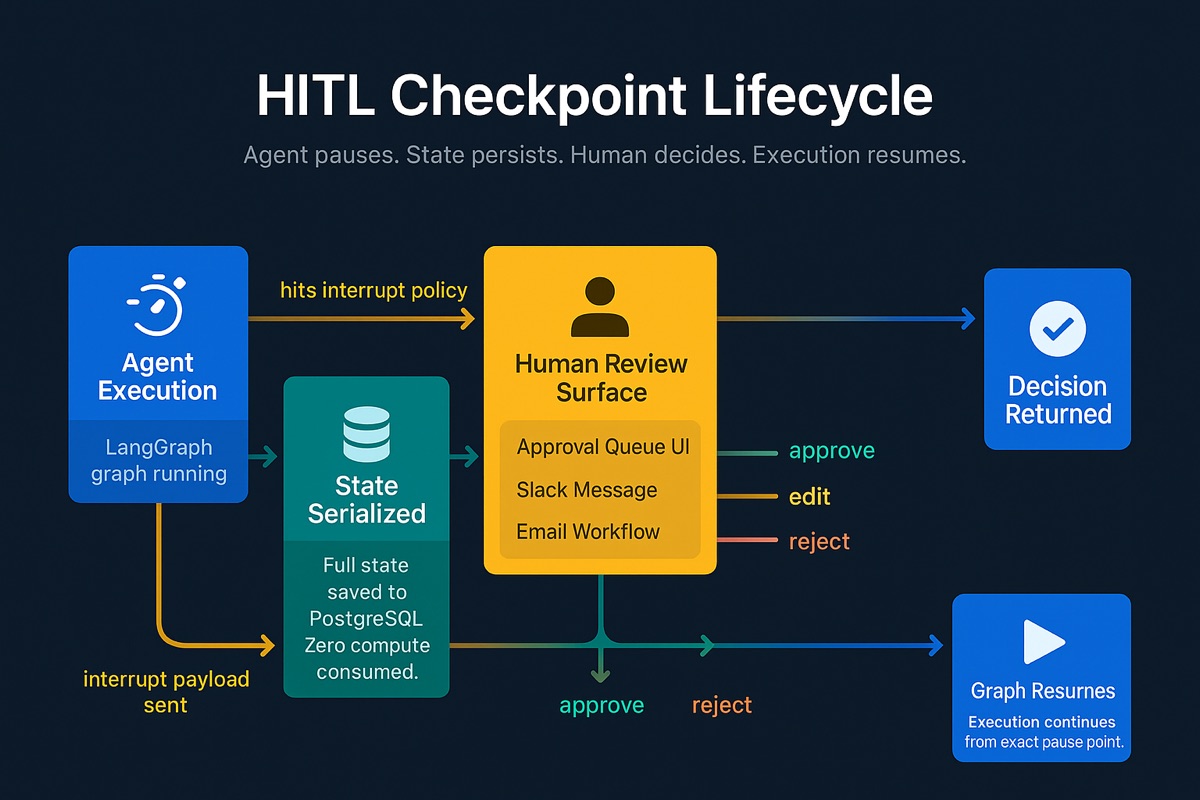
Build HITL Checkpoints into the Agent Graph
The agent must be able to pause, persist its state indefinitely, and resume from exactly where it left off. Skip this and you either block the execution thread (unacceptable) or lose context and force a restart (equally unacceptable).
Strongly Workflows provide the right abstraction. The platform offers a Human Checkpoint node as a first-class workflow primitive. When execution reaches a Human Checkpoint, the workflow serializes its entire state to Kubernetes-native persistent storage and suspends. No thread stays alive. No compute is consumed while waiting.
Production requirement: Strongly Workflows run on Kubernetes with built-in state persistence. Every workflow node's inputs, outputs, and timing are automatically captured - no separate checkpointer configuration needed.
# Strongly Workflow — Accounts Payable with Human Checkpoints
name: "accounts-payable-review"
description: "Invoice processing with human approval gates"
nodes:
- id: "read_invoice"
type: AgentNode
config:
model: "claude-sonnet-4-6"
tools: ["read_invoice_tool"]
- id: "payment_approval"
type: HumanCheckpoint
config:
title: "Pending approval"
allowed_decisions: ["approve", "reject"]
show_context: true
- id: "execute_payment"
type: AgentNode
config:
tools: ["execute_payment_tool", "update_vendor_record_tool"]
edges:
- from: "read_invoice" → "payment_approval"
- from: "payment_approval" → "execute_payment"
condition: "{{ input.decision }} === 'approve'"
Architecture note: Don't store large artifacts (PDFs, binary files) directly in workflow state. Store reference URIs and keep artifacts in object storage. Strongly Workflows persist state at every node transition, so a 50MB document across 10 steps creates 500MB of storage writes.
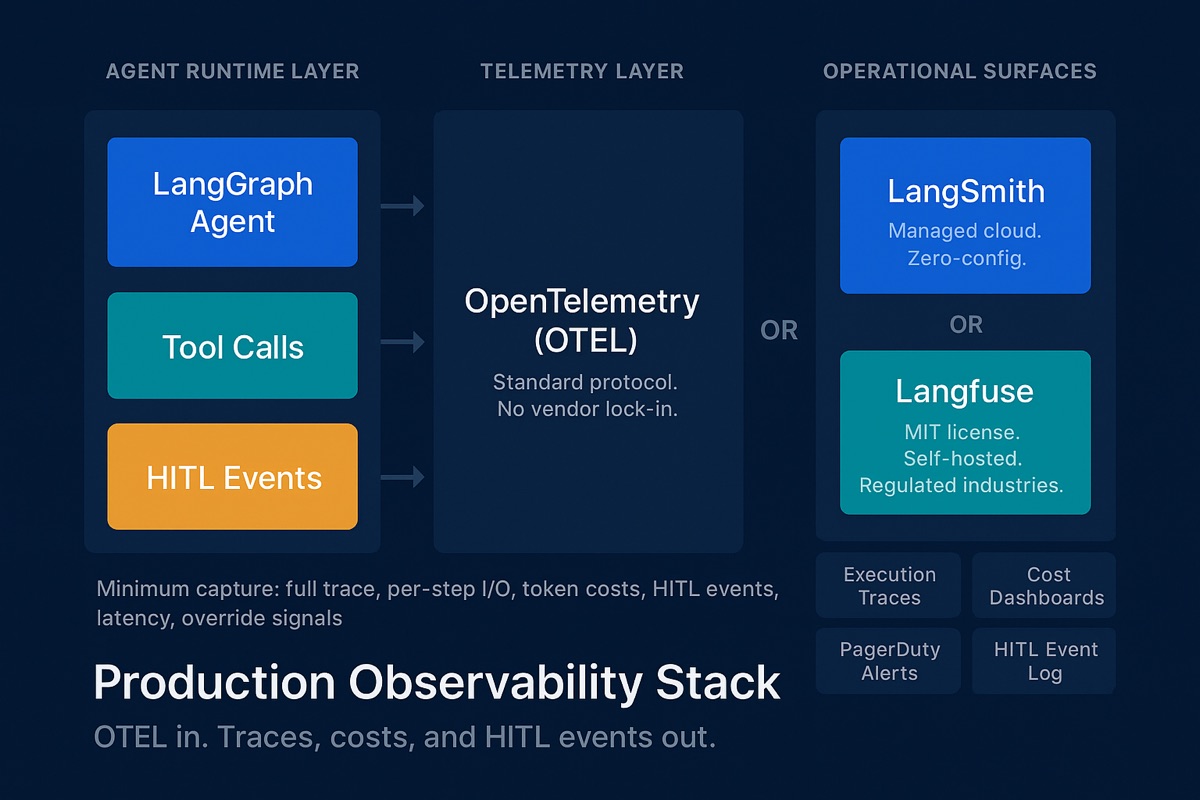
Instrument the Full Observability Stack
Without comprehensive observability, you cannot diagnose failures, demonstrate compliance, or optimize performance. This is where most platforms leave teams stranded.
The industry is converging on OpenTelemetry (OTEL) as the standard telemetry protocol. Most mature frameworks emit OTEL-compatible traces natively. Building on OTEL prevents vendor lock-in and integrates into existing monitoring infrastructure.
Production Backend Options
Strongly Built-in Tracing
Native per-node execution tracing with zero configuration. Captures complete execution traces - every LLM call, tool invocation, state transition, token usage, latency, and cost. Per-node timing, inputs, outputs, and logs viewable directly in the workflow builder.
OTEL-Compatible Backends
Strongly emits OpenTelemetry-compatible traces natively, so you can route to any OTEL backend - Datadog, Grafana, or a self-hosted collector. No vendor lock-in; fits into your existing monitoring stack.
Minimum Viable Observability
Your observability schema must capture these seven requirements. Click each to check it off:
“When a human rejects or edits an agent's output, that is a high-signal training event. Most teams instrument the happy path and miss this entirely.
Design the Multi-Agent Routing Layer
Most enterprise systems are networks of specialized agents orchestrated by a supervisor. A claims system might have document extraction, policy lookup, fraud scoring, and compliance agents all contributing to one human-facing workflow.
Strongly's Supervisor Agent node is the right architecture. A Supervisor Agent receives the task, orchestrates sub-agents, and routes via Conditional control flow nodes. After completion, the supervisor decides next steps. The DAG is explicit - every transition is traceable, every HITL checkpoint has a deterministic trigger.
# Strongly Workflow — Claims Processing with Supervisor Routing
name: "claims-supervisor"
description: "Multi-agent claims processing with conditional routing"
nodes:
- id: "supervisor"
type: SupervisorAgent
config:
sub_agents: ["document_agent", "policy_agent", "fraud_agent"]
- id: "document_agent"
type: AgentNode
config: { tools: ["extract_documents"] }
- id: "policy_agent"
type: AgentNode
config: { tools: ["lookup_policy"] }
- id: "fraud_agent"
type: AgentNode
config: { tools: ["score_fraud"] }
- id: "fraud_check"
type: Conditional
condition: "{{ input.fraud_score }} > 0.85"
- id: "human_review"
type: HumanCheckpoint
config:
title: "High fraud score — manual review required"
allowed_decisions: ["approve", "reject", "escalate"]
edges:
- from: "supervisor" → "fraud_check"
- from: "fraud_check" → "human_review" # if true
- from: "fraud_check" → "complete" # if false
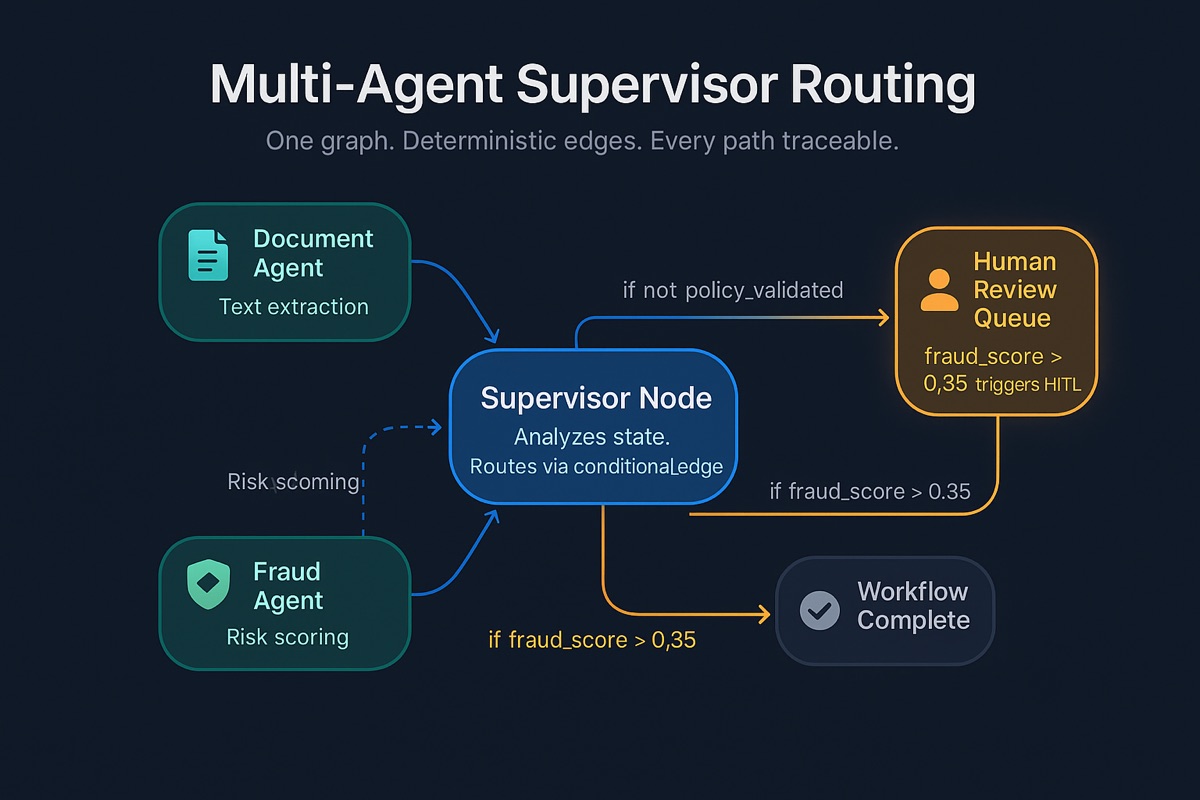
The human_review node fires the HITL interrupt. The fraud agent sets a score; the supervisor evaluates it; scores above threshold route to human review. The human sees full state - extracted content, policy results, fraud score with contributing factors - not just a binary prompt.
The output of the supervisor determines not just which agent runs next, but which surface the human sees. Low confidence triggers chat clarification. High stakes triggers an approval queue. Routine completion writes to a dashboard aggregate.
How StronglyAI Makes This Tractable
Getting HAIL right is achievable but requires engineering discipline, workflow analysis, and operational expertise most organizations are building from scratch simultaneously.
Platform + People + Process
Platform
Production-grade Kubernetes-native state persistence for HITL workflows, built-in per-node execution tracing with OTEL compatibility, and 100+ containerized MCP servers connected and governed. Drag-and-drop workflow builder with Human Checkpoint nodes, Supervisor Agents, and Conditional routing - all with visual inspection at every node.
People
Forward Deployed Engineers sit with actual users, map who needs what format under what time pressure, build approval queues, wire observability, design supervisor routing, and transfer knowledge through documentation and pairing.
Four-Phase Methodology
Assess
Map the decision frequency and error consequence matrix for every workflow.
Deploy
Wire observability from day one. Instrument HITL checkpoints with production-grade persistence.
Amplify
Use HITL event data to identify friction points and optimize interface formats.
Scale
Override signals drive architecture decisions about automating manual checkpoints.
The Architecture in Four Pieces
This is the complete HAIL architecture. Four moving pieces, each with clear implementation patterns:
Interface Format Selection
Driven by decision frequency and error consequence. Map every persona to the right surface.
HITL Checkpoints
Built on Strongly's Human Checkpoint node with Kubernetes-native persistence. Pause, persist, resume without losing context.
Full Observability Stack
Strongly's built-in per-node tracing with OTEL compatibility. Capture every trace, every cost, every human override.
Multi-Agent Routing
Strongly's Supervisor Agent with Conditional nodes. Route to the right agent and the right human surface.
“Get these four things right and you have a system people actually use. Get them wrong and you have a demo that never makes it to production.
References
- McKinsey's 2025 State of AI
- Deloitte 2025 Emerging Technology Trends
- UX for Agentic AI - UX Matters
- Strongly Workflows Documentation
- OpenTelemetry Documentation
Ready to Build Your Interface Layer?
Our Forward Deployed Engineers will design, wire, and optimize the HAIL architecture for your enterprise workflows.
Scope the First Engagement