Fine-Tune Models. No ML Team Required.
60+ Hugging Face models. Upload your data. Click train. Point-and-click fine-tuning that works for business users, not just data scientists.
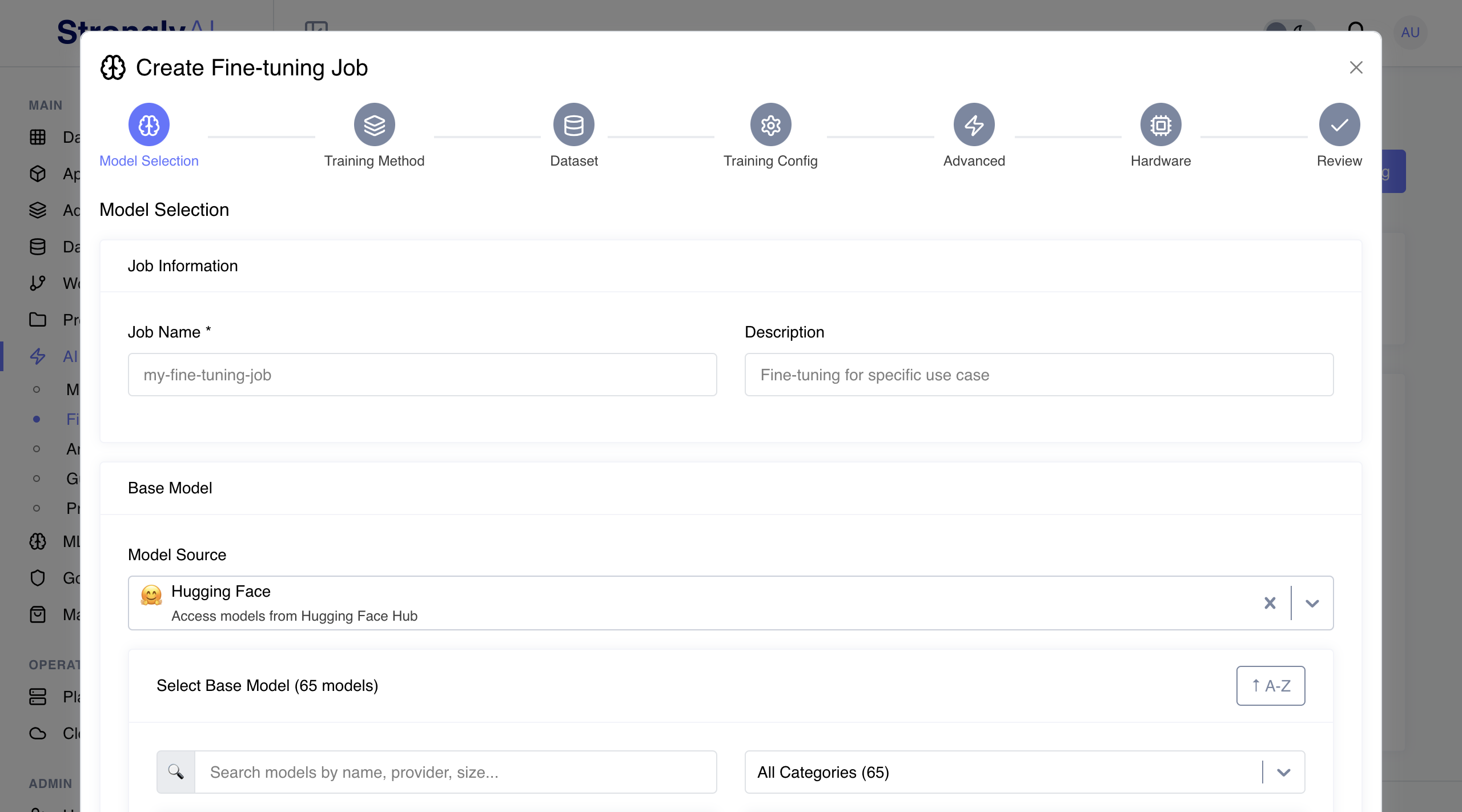
Select. Upload. Train. Deploy.
Four steps from generic model to domain-specific production model
Simple Data Upload
Drag-and-drop your training data. Built-in validation catches formatting issues. 100 examples minimum. No data engineering pipeline required.
60+ Hugging Face Models
Llama, Mistral, Flan-T5, and 60+ more from Hugging Face. Browse the catalog. Pick the right base model. Start training in minutes.
Guided Configuration
Learning rate, batch size, epochs - all configurable with intelligent defaults. The platform recommends optimal settings. You decide.
Training Monitoring
Real-time loss curves, validation scores, and training metrics. Spot problems early. Stop wasting GPU hours on runs that will not converge.
Model Evaluation
Test against benchmarks and custom test sets. Compare runs side-by-side. Deploy the model that actually performs best, not the one that feels right.
One-Click Deployment
Deploy to production endpoints with one click. Auto-scaling and integration with your existing apps. From training to serving in minutes.
Three Methods. Pick What Fits.
Match your fine-tuning approach to your hardware and performance requirements
LoRA (Low-Rank Adaptation)
Adds small trainable matrices to model layers while freezing original weights. Memory efficient with 90% less than full fine-tuning and faster training times.
QLoRA (Quantized LoRA)
LoRA with 4-bit quantization of the base model. Extremely memory efficient with 95% less than full fine-tuning. Fine-tune large models on limited hardware.
Full Fine-tuning
Updates all model weights for maximum customization potential. Requires most computational resources but delivers highest performance for specialized tasks.
Generic Models Are Not Good Enough
Fine-tuned models cost less per call and produce better results. The math is simple.
No PhD Required
Point-and-click interface with guided workflows. Business users fine-tune models. Data scientists focus on harder problems.
Your Data. Your Domain.
Models learn your terminology, context, and requirements. Accuracy that generic models cannot match. Because they were not trained on your data.
80% Fewer Tokens
Fine-tuned models need shorter prompts and produce better outputs. Less tokens, lower costs, higher accuracy. All three.
Your Model. Your Data. Period.
Training data stays private. Fine-tuned models are yours. No shared weights, no data leakage, no compliance risk.
Custom Models. Production-Ready.
Our FDEs will identify which models to fine-tune and what data you need to start.