Where we are in the stack: the memory pattern that dominates everything during decode. We have the weights loaded (Part 2) and we know how a forward pass computes (Part 3). Now we ask what gets remembered between forward passes and what it costs.
In Part 3 we walked one token through a transformer and noticed that the attention block needs to look at every prior token in the context. If naive, each decode step would reprocess the entire prefix. That would turn a 1000 token generation into 1000 + 999 + 998 + ... = 500,500 token-equivalents of work. Quadratic, intolerable.
The fix is the KV cache, and once you understand it you understand why modern serving systems put so much engineering into one tensor.
Why K and V are cached, but Q is not
The attention computation inside a single layer, for the token currently being generated, looks like this:
Q = x @ W_Q # 1 query for the new token
K_new = x @ W_K # 1 new key for the new token
V_new = x @ W_V # 1 new value for the new token
K_full = concat(K_cached, K_new)
V_full = concat(V_cached, V_new)
attn = softmax(Q @ K_full.T / sqrt(d)) @ V_fullThe new token's Q vector queries against every prior K and pulls weighted information from every prior V. To compute attention for a single new token, we need K and V for all prior tokens, but only Q for the new token.
Computed once for the new token, then thrown away.
Compute K for new token, append to cache, read all prior K's.
Compute V for new token, append to cache, read all prior V's.
So Q is computed fresh for the new token every step. K and V from prior tokens never need to be recomputed, because they only depend on those tokens' own input vectors and the (frozen) weight matrices. Cache them once, read them forever.
“The KV cache is the data structure that turns a quadratic algorithm into a linear one.
Sizing the KV cache
Per token, the KV cache stores K and V tensors of shape [n_kv_heads, head_dim] in each layer. Total bytes per token:
kv_per_token = 2 * n_layers * n_kv_heads * head_dim * bytes_per_valueThe factor of 2 is for K and V. Plug in real models, BF16:
The numbers are sneaky in how fast they grow. At a 128k token context (which several modern models support), Llama 3 70B needs 40 GB of KV cache for one sequence. The model itself is 140 GB. Already 28% of model memory.
This is before you batch. If you want to serve 32 concurrent users at 8000 tokens each on Llama 3 70B, the KV cache total is 80 GB. On an H100 (80 GB) you cannot fit both the model and the KV cache in the same GPU. You need multiple GPUs, smaller batches, shorter contexts, KV cache quantization, or some combination.
Why long context blows up VRAM faster than people expect
Three independent effects pile up.
- Linear scaling with sequence length. Doubling context doubles KV cache.
- Linear scaling with batch size. Doubling concurrent users doubles KV cache.
- The KV cache must be in VRAM to be useful. Unlike model weights, which you read once per step, the KV cache is involved in attention computation. The attention kernel reads it heavily and writes one new token's worth to it per step. Storing it on CPU or NVMe means PCIe round trips on every layer of every decode step, which is unacceptable for most workloads (though there are exceptions, which we will get to).
Combined, you can quickly hit a regime where the KV cache is larger than the model. For Llama 3 70B serving long context users, the KV cache often exceeds the model weights by 2x or 3x in total VRAM. The serving system's job is largely to manage this.
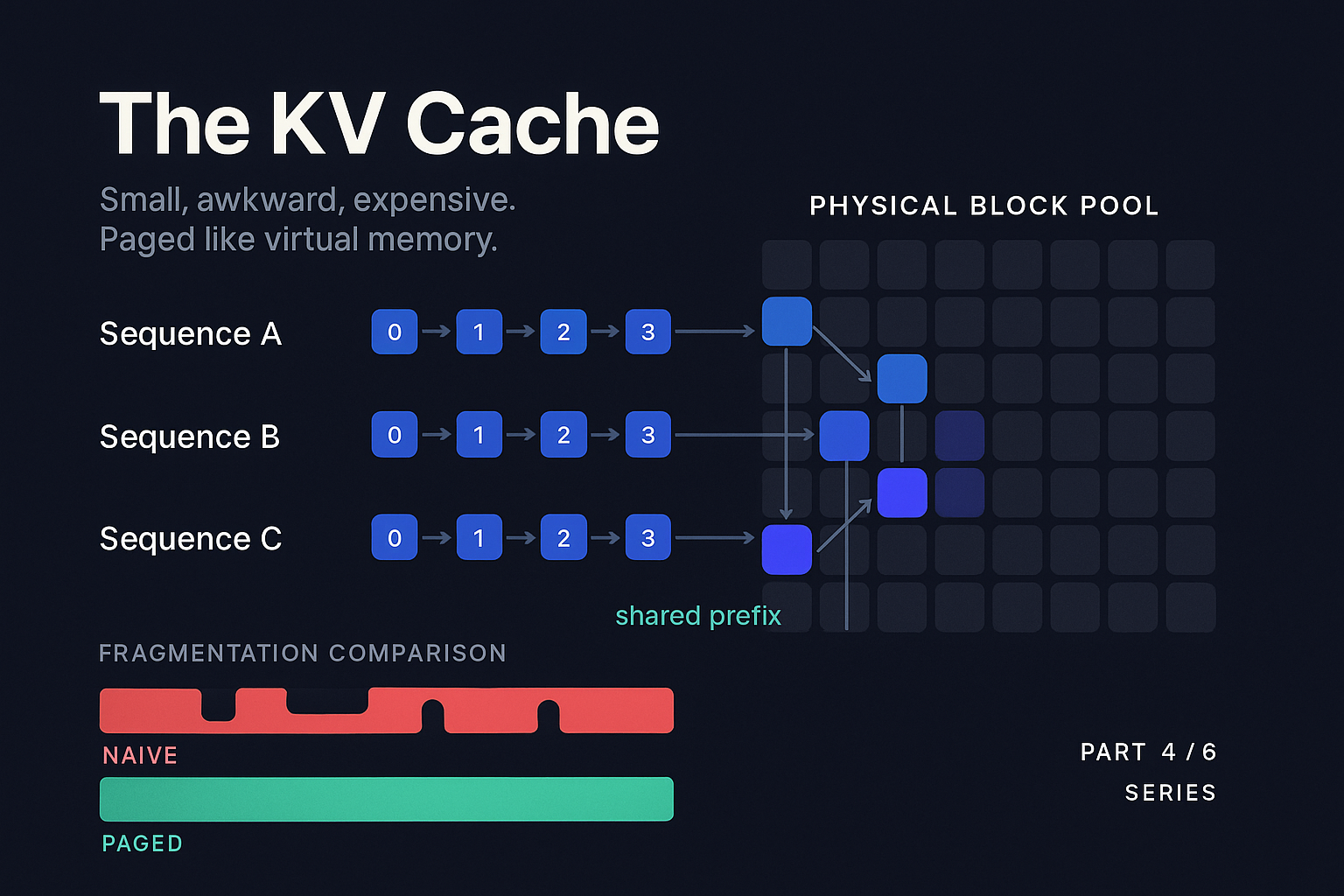
The fragmentation problem
Suppose you have 40 GB of VRAM available for KV cache after loading the model. You receive a request with a 4000 token prompt and the user wants up to 2000 new tokens. You don't know up front how many they will actually use. The model might emit an EOS at token 100 or run all the way to 2000.
Naive allocation reserves enough KV cache for the worst case. 4000 + 2000 = 6000 tokens. For Llama 3 70B that is 1.92 GB per request. You can fit 20 such requests in 40 GB. But if most requests only generate 200 tokens, you allocated for 2000, used 200, and wasted 1.8 GB per request. Your effective batch size collapses.
What if you allocate conservatively? Then a request that wants 2000 tokens has to be cut off, or you have to reallocate and copy. Reallocating GPU memory mid-sequence is painful. What if you allocate exactly the prompt length and grow as needed? Now every request grows independently, and after a few hundred requests have come and gone you have a swiss cheese pattern of allocated and free chunks. Classic fragmentation.
Reserve worst case per request
Allocate fixed-size blocks on demand
Kwon et al. measured this in their vLLM / PagedAttention paper (SOSP 2023). For typical workloads, naive allocation wasted 60% to 80% of KV cache memory. The actual computation was using only 20% to 40% of what was reserved. The fix changed how the industry builds serving systems.
PagedAttention: virtual memory for the KV cache
The vLLM team's insight was that the KV cache fragmentation problem is exactly the same problem that operating systems solved for process memory decades ago, using virtual memory and paging. The solution looks almost identical.
PagedAttention divides the KV cache into fixed size blocks (typically 16 tokens per block). Each block stores the K and V tensors for those 16 tokens, across all layers. The blocks are allocated from a global pool of physical blocks in VRAM. Each sequence has a block table that maps its logical token positions to physical block addresses, just like a page table maps virtual addresses to physical pages.
When a sequence wants to grow, the system allocates a new block from the pool and adds it to the sequence's block table. When a sequence finishes, all its blocks return to the pool. Crucially, the blocks for one sequence do not have to be contiguous in physical memory. Fragmentation drops to nearly zero because every allocation is the same size.
The attention kernel has to be aware of this structure. The PagedAttention kernel walks the block table for each sequence and gathers the right physical blocks as it does the attention math. This adds a small overhead per attention step (a few percent in practice) but the win in usable batch size is large. The vLLM paper showed 2x to 4x throughput improvements on real workloads, mostly from being able to fit more sequences in the same VRAM.
PagedAttention has become the default. vLLM, TensorRT-LLM, SGLang, and most internal company stacks all use some variant. Block size is sometimes 16, sometimes 8, sometimes adjustable per layer. The kernels have been re-tuned many times for different GPU generations. But the core idea is the 2023 vLLM paper, and it is one of the most influential systems papers in the LLM era.
Prefix caching and shared system prompts
The KV cache stores intermediate state for a sequence. If two sequences share a common prefix (the same system prompt, the same few-shot examples, the same RAG context), they will produce identical K and V tensors for those prefix tokens. Recomputing them for the second sequence is wasted work.
Prefix caching keeps prefixes in the KV cache pool across requests. When a new request comes in, the system hashes the input tokens (typically in blocks of N tokens to match the page size) and looks up matching blocks. If they exist, the new request's block table just points at them. Only the unique suffix needs new computation.
This is enormously useful in production. RAG systems retrieve documents and prepend them. Chatbots have a long system prompt. Agentic systems re-send context on every turn. With prefix caching, the prefill cost for these repeated prefixes goes to near zero (just the time to look them up).
vLLM has had Automatic Prefix Caching (APC) since 2024. SGLang's RadixAttention (Zheng et al., 2024) generalized this further with a radix tree over blocks, allowing efficient sharing of branching prefixes (think a chatbot with multiple parallel hypotheses). For multi-turn conversation serving, RadixAttention reported 2x to 5x throughput improvements over vLLM's APC on conversational benchmarks.
The accounting gets interesting. With prefix caching, the same physical block can be referenced by many sequences. You need a reference count. Eviction policy matters. LRU is the obvious default but in some workloads (e.g., where one shared prefix is overwhelmingly common) you want to pin it. There is real engineering here.
KV cache quantization
The KV cache is large. The KV cache is mostly bandwidth bound on read. The KV cache numerical precision does not need to be as high as the model weights need to be for math reasons. All three facts point at the same answer: quantize it.
Two approaches work in practice.
FP8 KV cache (per tensor or per head scales) is the most common production choice as of 2026. Hopper (H100) has native FP8 support, so the attention kernel can do the matmul directly in FP8 without dequantizing first. The accuracy hit is typically under 1% on standard benchmarks for well-implemented FP8 KV cache. TensorRT-LLM, vLLM, and SGLang all support it.
Sub-4-bit KV cache with carefully designed quantization is a more aggressive choice. Hooper et al.'s KVQuant (2024) compounds several tricks (per-channel keys, pre-RoPE key quantization, non-uniform per-layer datatypes, dense-and-sparse) to reach sub-4-bit precision with under 1% perplexity degradation. Liu et al.'s KIVI (2024) goes further, reaching asymmetric 2-bit quantization with a clean recipe: quantize K per-token (along sequence dimensions) and V per-channel (along feature dimensions). This asymmetry isolates the outliers cleanly because K outliers cluster by token (position) while V outliers cluster by channel. The downside in both cases is that low-precision attention kernels are not native on most current hardware, so you pay a dequantization cost.
Offloading: when CPU and NVMe come back
We said earlier that the KV cache needs to be in VRAM. That is true for the active part of attention. But not all of the KV cache is active all the time.
In a long conversation, the most recent tokens get attended to heavily and the very oldest tokens get attended to lightly. Many practical scenarios have this property: the model rarely attends strongly to tokens beyond a few thousand back. Attention sinks (Xiao et al., 2023) show that the first few tokens of context often act as a high-weight anchor regardless of what follows, while middle tokens decay in influence.
This opens up offloading strategies. Keep the recent K/V blocks and the attention sink blocks in VRAM. Push the middle blocks to CPU RAM or NVMe. When needed, swap them back in via PCIe.
HBM (VRAM)
Recent K/V + attention sinks. Decode-path data must live here.
Host RAM
Middle-context K/V blocks. Swap in on demand. Useful for long context.
NVMe
Archive tier for 1M+ token contexts or rarely-accessed conversations.
This is a tradeoff. PCIe is much slower than HBM. Reading 1 GB of KV cache over PCIe costs about 20 milliseconds, versus 0.3 milliseconds from HBM. For decode that is catastrophic. But:
- For some agentic workloads that re-read very long contexts only occasionally, the latency hit is acceptable
- For prefill on very long contexts where you would otherwise OOM, offloading is the difference between serving the request and not
- For research workloads that need 1M+ token contexts on consumer hardware, it is essentially the only option
Frameworks like FlexGen (Sheng et al., 2023) and DeepSpeed-Inference have built sophisticated offloading systems. For most production serving, offloading is not the right tool. For long-context inference with intermittent access patterns or for memory-constrained setups, it is.
Putting it together: a request's KV story
Let's walk through what happens to the KV cache during one request on a modern serving system (call it vLLM-style with prefix caching and PagedAttention).
Request arrives
2000 token prompt. First 1500 are a common system prompt + RAG header the system has seen before.
Prefix lookup
Hash the first 1500 tokens in 16-token blocks. Find 94 cached blocks. Build the block table to point at them.
Prefill the unique suffix
500 remaining tokens go through prefill. 32 new blocks (500 / 16 rounded up) allocated from the pool and populated.
First decode step
Attention gathers from 126 physical blocks (94 shared + 32 unique) via the block table. Write 1 K and 1 V vector for the new token into a fresh block.
Decode continues
Every 16 tokens generated, a new block is allocated. The block table grows.
Request finishes (200 tokens)
13 newly allocated blocks return to the pool. 94 prefix blocks remain in the cache for the next user. 32 unique-suffix blocks evicted.
This is the everyday life of one tensor that, in 2017, the original transformer paper barely thought about.
What to take away
The KV cache is the memory pattern that turns autoregressive generation from quadratic to linear. It is the thing you spend the most VRAM on in production for long-context workloads. Naive management wastes most of it. PagedAttention solves the fragmentation problem by paging it like virtual memory. Prefix caching exploits redundancy across requests. Quantization halves or quarters its footprint. Offloading is sometimes the right escape hatch.
When you are sizing inference hardware, you are mostly sizing the KV cache. When you are debugging OOMs on a serving system, you are mostly debugging KV cache allocation. When you are improving throughput, you are mostly improving how many sequences' KV caches you can keep alive at once.
In Part 5 we look at the scheduling layer on top: how to actually get many requests through the same model at the same time.
Batching and Serving
References and further reading
- Kwon et al., 2023. "Efficient Memory Management for Large Language Model Serving with PagedAttention." SOSP 2023. arXiv:2309.06180. (Essential.)
- Zheng et al., 2024. "SGLang: Efficient Execution of Structured Language Model Programs." arXiv:2312.07104. (Introduces RadixAttention.)
- Hooper et al., 2024. "KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization." arXiv:2401.18079.
- Liu et al., 2024. "KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache." arXiv:2402.02750.
- Xiao et al., 2023. "Efficient Streaming Language Models with Attention Sinks." arXiv:2309.17453.
- Sheng et al., 2023. "FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU." ICML 2023. arXiv:2303.06865.
- Ainslie et al., 2023. "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints." arXiv:2305.13245.
OOMing on long-context users?
Strongly.AI's forward deployed engineers have shipped KV cache management for everything from small chatbots to multi-million-token agentic workloads. If your GPU memory math doesn't add up, we'll find what's eating it.
Schedule A Demo