Where we are in the stack: the final piece. Quantization crosscuts every layer we have built up. It changes how weights are loaded (Part 2), how the forward pass computes (Part 3), how the KV cache is stored (Part 4), and how serving systems are sized (Part 5). This post pulls it all together.
Every tensor in an LLM is a pile of floating point numbers. In training, they are typically BF16 or FP32 because gradient stability needs the precision. In inference, you do not need that precision. The model already learned what it is going to learn. You just need to multiply some matrices and get reasonable outputs.
Quantization is the practice of storing tensors in fewer bits than they were trained in. The benefit is straightforward: fewer bits means less memory and less bandwidth. The cost is that lower precision can hurt model quality, and pushing too far can break the model entirely. The art is figuring out how few bits you can get away with for each kind of tensor, and how to do the arithmetic at low precision without destroying numerical stability.
This post walks through what gets quantized, the techniques used, and how they interact. It is the most practical post in the series, in the sense that knowing this material directly translates to "how much does it cost to serve this model".
Why quantization works at all
A common reaction to "store 7B parameters in 4 bits each" is "that has to lose information". It does. The question is whether the information lost matters for the model's outputs.
Two empirical facts make quantization viable.
- Most weight values are small and clustered. Trained model weight distributions are roughly Gaussian with a heavy tail. The mass of the distribution sits in a narrow range. Linear quantization (uniform spacing of representable values) wastes representation on rare outliers but captures the typical case well.
- Matrix multiplication averages quantization noise. When you multiply a quantized matrix by an input vector, you sum up many products. Independent quantization errors partially cancel. The output is far closer to the unquantized result than the per-element error would suggest.
The catch is that "independent" is a strong assumption, and certain layers (especially activations) have correlated outliers that do not cancel. Most of quantization research is about identifying and handling these cases.
A useful theoretical reference: Frantar and Alistarh, 2022, "Optimal Brain Compression" formalized the idea of choosing quantization values to minimize the output error rather than the weight error, which underlies most modern weight quantization techniques.
Three things to quantize
LLM inference has three tensors of dramatically different sizes and access patterns. Each gets quantized differently.
Weights
Static. Loaded once, read many times. Well-behaved distributions analyzed offline.
Activations
Computed fresh every step. Input-dependent. Aggressive outliers after attention.
KV Cache
Computed once per token, read many times. Asymmetric K vs V outlier patterns.
Weight quantization
Weight quantization happens once, offline, before the model is deployed. You take a trained model, run an analysis, and produce a quantized model that can be loaded for inference. The question is how to choose the quantized values.
Linear quantization. The simplest approach. For each weight matrix, find the min and max, divide the range into 2^B equal buckets (for B bit quantization), and round each weight to the nearest bucket. Store a scale and zero point along with the integer weights. In older serving systems, the weights would be dequantized back to floating point before matrix multiplication, incurring an overhead.
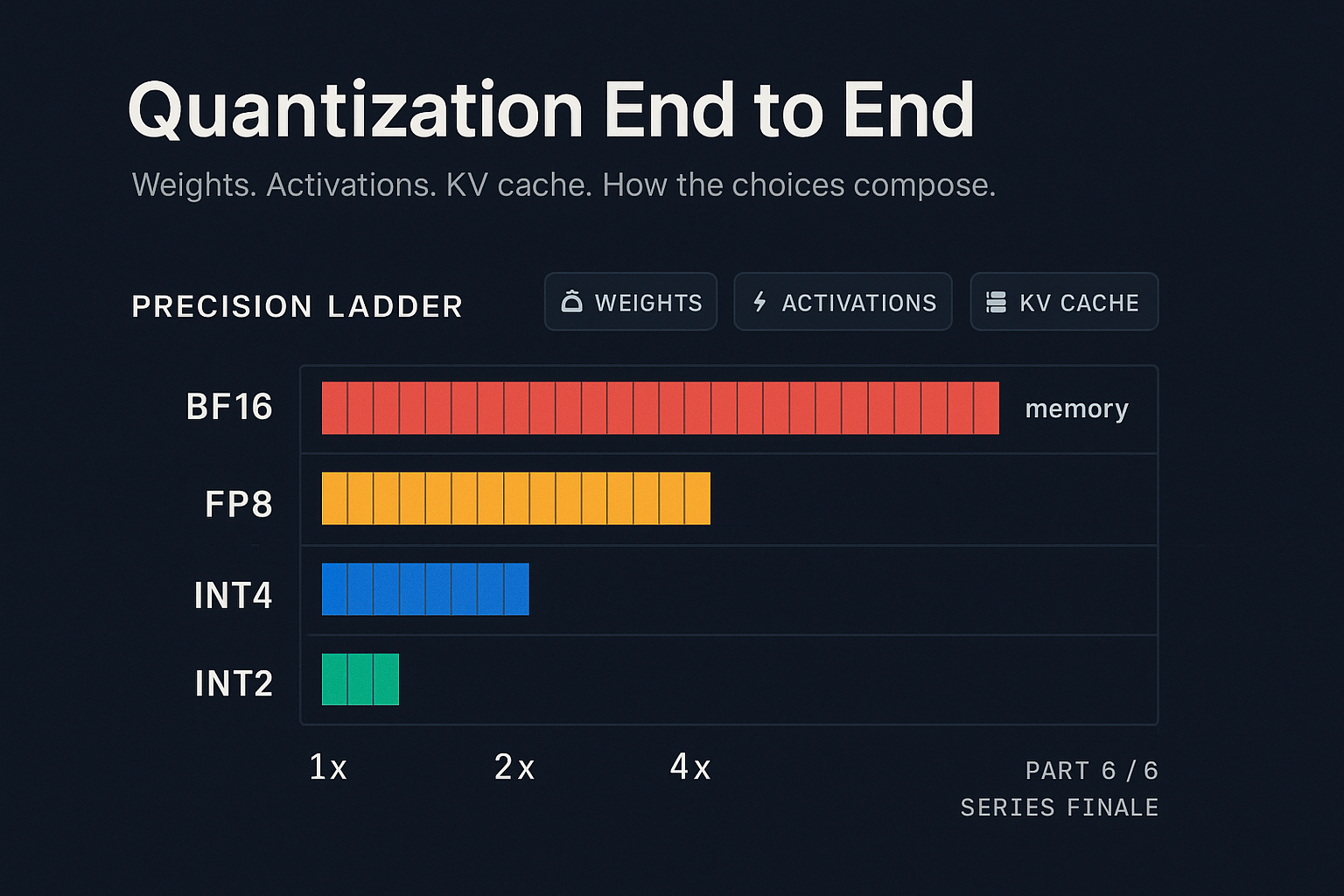
Linear quantization works fine to INT8 and gives 2x compression with negligible accuracy loss on most models. Below INT8, naive linear quantization starts losing accuracy fast because outlier weights dominate the range and squash the precision available to the rest.
Group-wise / per-channel quantization. Instead of one scale for the whole matrix, use one scale per group of weights (commonly 128 weights per group) or one scale per output channel. This gives the outliers their own scale and lets the typical-magnitude weights have higher precision. Most production INT4 schemes use group sizes of 32 to 128.
GPTQ (Frantar et al., 2022) is the technique that made 4-bit weight quantization production-viable. GPTQ quantizes weights one column at a time, and after each column is quantized, it updates the remaining unquantized weights to compensate for the error introduced. This is the same idea as Optimal Brain Surgeon (Hassibi and Stork, 1992) applied at scale, with clever approximations to keep it computationally feasible for billion-parameter models.
GPTQ on Llama 3 70B in INT4 typically gets within 1% of BF16 perplexity, while cutting weight memory from 140 GB to 35 GB. That single change can take a model from "needs four H100s" to "fits on one H100".
AWQ (Lin et al., 2023) observed that the weights that matter most for output quality are the ones that get multiplied by large activations. AWQ identifies these "salient" weights (typically about 1% of parameters) and protects their precision, while quantizing the rest aggressively. The hardware advantage is that AWQ does not require mixed precision; instead it uses activation-aware per-channel scaling to ensure uniform quantization preserves the precision of these salient weights. Implementation is simpler than GPTQ in some ways. Accuracy is similar.
FP8 (with two variants, E4M3 and E5M2) is hardware-native on Hopper (H100) and Blackwell. Unlike INT8 it has a non-uniform spacing of representable values (more precision near zero, less precision near the extremes) which matches weight distributions better. The big advantage is that FP8 matmul kernels are first-class on modern hardware, so there is no dequantize-then-multiply overhead. Quality is excellent. Memory savings is 2x vs BF16. E4M3 is typically used for weights.
FP4 / NF4 / INT4 with sub-byte packing. FP4 (4 bit floating point) is supported on Blackwell. The NF4 format (Dettmers et al., 2023, "QLoRA") uses information theoretic bucket placement tuned to normal distributions and matches GPTQ INT4 in accuracy with simpler quantization. INT4 is still the workhorse for older hardware. All compress weights 4x vs BF16.
A practical observation: the accuracy hit from weight quantization is dramatically smaller for large models than for small ones. A 7B model takes a real hit going to INT4. A 70B model barely notices. This is one of several reasons why most production deployments serve 70B+ models in 4-bit weights.
Activation quantization
Activations are harder to quantize than weights for two reasons. First, they depend on the input, so you cannot analyze them ahead of time the way you can analyze weights. Second, they have outliers.
The outlier problem is real and well-documented. Bondarenko et al. (2021) and Dettmers et al. (2022, "LLM.int8()") showed that in transformer activations, a small number of feature dimensions consistently produce values 100x or 1000x larger than the average. These outliers wreck naive quantization because they force the scale to be huge, squashing the rest of the activations into a few buckets near zero.
LLM.int8() handled outliers by doing mixed precision: dimensions with outliers stay in FP16, the rest go to INT8. The compute uses a custom kernel that splits the matmul accordingly. It works but the kernel is complex and the memory layout is awkward.
SmoothQuant (Xiao et al., 2022) took a different approach. The outliers are in activations, not weights. So SmoothQuant moves the outlier difficulty into the weights by mathematical equivalence. If you scale the activations down by s and the corresponding weight rows up by s, the matmul output is unchanged. Choose s to flatten the activation outliers, and now both weights and activations are in a regime that quantizes well.
This is now a standard technique in many production stacks.
FP8 activations are increasingly the production answer. On Hopper, you can do the full matmul in FP8 (FP8 weights times FP8 activations), with FP32 accumulation, and only convert back to BF16 at residual connections. NVIDIA's TransformerEngine library handles the scaling automatically and reports near-BF16 quality on Llama-class models. Throughput goes up significantly because the H100's FP8 tensor cores have twice the throughput of BF16. This usually uses the E5M2 variant to capture activation outliers.
The general lesson: activation quantization is harder than weight quantization, requires hardware support for the matmul to actually be faster (not slower from dequantize overhead), and outliers force you to either use mixed precision or shift the difficulty around. As of 2026, FP8 activations are the production sweet spot for Hopper and Blackwell hardware. INT8 activations with SmoothQuant are common on hardware without FP8 support.
KV cache quantization
We previewed this in Part 4. The KV cache is in some ways the highest-leverage tensor to quantize, because it grows with context length and serving it efficiently determines how many concurrent users you can support.
The K and V tensors have their own distribution quirks. Outliers in K are correlated with positions (some token positions produce large K values). Outliers in V are correlated with channels (some feature dimensions are larger). The asymmetry matters.
FP8 KV cache is the most common production choice. Per-tensor or per-head scales work well for FP8 because FP8's non-uniform spacing handles moderate outliers gracefully. The accuracy hit is typically under 1% on standard benchmarks. Memory and bandwidth halve. Hopper hardware supports FP8 attention kernels natively, so there is no dequantize cost.
Sub-4-bit KV cache is more aggressive. The two papers worth knowing are KVQuant (Hooper et al., 2024) and KIVI (Liu et al., 2024). KVQuant compounds several techniques (per-channel keys, pre-RoPE key quantization, non-uniform per-layer datatypes, dense-and-sparse decomposition) to reach sub-4-bit precision. KIVI is more aggressive still, hitting asymmetric 2-bit with a clean recipe: quantize K per-channel (along feature dimensions) and V per-token (along sequence dimensions). Both report under 1% perplexity degradation on most benchmarks.
The memory math for Llama 3 70B at 128k context, single user:
BF16 KV cache: 40 GB · FP8: 20 GB · INT2 (KIVI-style): 5 GB. For a serving system trying to fit many users, the difference is multiplicative on concurrent batch size.
A subtlety: KV cache quantization happens online (per-token, during decode), so the quantize/dequantize cost matters. For FP8 on hardware with native FP8 attention, the cost is negligible. For sub-4-bit you need a custom attention kernel that does the dequantize inside the kernel, ideally fused with the matmul. vLLM, TensorRT-LLM, and SGLang all ship such kernels as of 2026.
How quantizations interact
Picking quantization configurations is not three independent choices. They interact.
- Weight quantization affects activation quantization. If you scale weights using SmoothQuant to manage activation outliers, you have less headroom for aggressive weight quantization. INT4 weights + INT8 activations works well. INT4 + INT4 is research-grade.
- Weight quantization changes the compute profile. Recall the roofline from Part 3. With INT4 weights, the bandwidth requirement to read weights drops 4x. Decode latency drops in proportion. But arithmetic intensity changes too: fewer bytes per FLOP means the compute roof becomes more visible. At very low precisions, dense decode can shift from bandwidth-bound to compute-bound.
- KV cache quantization stacks with everything else. Mostly independent of weight quantization choices. INT4 weights with FP8 KV cache, or BF16 weights with INT4 KV cache, in any combination.
- Numerical stability is a system property. When you quantize many tensors aggressively at once, errors that were individually small can compound. Validate end-to-end on a real benchmark, not just on individual layers.
How quantization changes the cost model
Recall that decode latency is typically dominated by weight reads (especially at BF16). If your weights are in INT4 instead of BF16, the bandwidth required to read them drops by 4x. Since decode is bandwidth-bound at BF16, this translates to a roughly 4x speedup in decode throughput on the same hardware, assuming kernel quality keeps up. This is a real number. You can verify it on any modern serving stack.
This "kernel quality" is typically only delivered by optimized serving frameworks like vLLM, TensorRT-LLM, or SGLang, not general PyTorch.
The implication for serving economics is large. A model that needs four H100s in BF16 might fit on one H100 in INT4. The cost per million tokens for that model drops 4x just from weight quantization, before any batching or scheduling improvements.
The decision of "what hardware do I need to serve this model" is much more about quantization choices than about raw model size. A 70B model in INT4 is not really a 70B model from a serving perspective. It is a 35 GB blob with the bandwidth profile of a 35 GB blob.
The accuracy tradeoff has to be measured on your actual workload. Standard benchmarks (MMLU, GSM8K, HumanEval) capture some of the impact but not all of it. If your domain is sensitive to specific factual recall or numerical precision in reasoning, quantization can hurt in ways that don't show up on general benchmarks. Always evaluate on your own evals before committing to a configuration.
What to take away
Quantization is the most leveraged optimization available to inference engineers in 2026. A well-quantized 70B model serves 4x more tokens per dollar than the same model in BF16, with single-digit-percent accuracy impact on most workloads.
The three tensors to think about are weights (easiest, biggest win), activations (harder, needs hardware support), and KV cache (high leverage for long context).
The standard configurations have stabilized: FP8 everywhere for high-quality default deployment, INT4 weights for memory-constrained settings, INT4 KV cache for long-context optimization.
The interactions between quantization choices matter. Validate end to end on your real workloads. Standard benchmarks are a starting point, not a finish line.
Series recap
Six posts in, here is the map of what we covered.
How LLM Inference Actually Works
Inference is sequential. Prefill and decode are different workloads. Three resources constrain everything.
PART 2The Weights' Journey into GPU Memory
File formats, NVMe to VRAM, page cache, PCIe, what optimized loaders do.
PART 3Inside the Forward Pass
Layers, FLOPs, bytes, arithmetic intensity, the roofline, FlashAttention.
PART 4The KV Cache
Why it exists, fragmentation, PagedAttention, prefix caching, quantization, offloading.
PART 5Batching and Serving
Continuous batching, chunked prefill, disaggregation, speculative decoding, SLO scheduling.
PART 6 / FINALEQuantization End to End
Weights, activations, KV cache, and how the choices interact.
“The model is a function, the GPU is a constrained machine, and almost every interesting engineering problem in LLM inference comes from the mismatch between the algorithm and the hardware. Each layer of the stack exists to manage some part of that mismatch.
If you want to go deeper on any single component, the references in each post are the best places to start. If you want to build production inference systems, read the source code of vLLM, TensorRT-LLM, and SGLang carefully. The papers describe the ideas; the code shows how the ideas survive contact with real systems.
That is the inference stack, from a single token to a production service.
Thanks for reading all six. If you want to be told when we publish the next series, you can subscribe below.
References and further reading
- Frantar et al., 2022. "GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers." arXiv:2210.17323.
- Lin et al., 2023. "AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration." arXiv:2306.00978.
- Dettmers et al., 2022. "LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale." NeurIPS 2022. arXiv:2208.07339.
- Dettmers et al., 2023. "QLoRA: Efficient Finetuning of Quantized LLMs." NeurIPS 2023. arXiv:2305.14314. (Introduces NF4.)
- Xiao et al., 2022. "SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models." arXiv:2211.10438.
- Hooper et al., 2024. "KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization." arXiv:2401.18079.
- Liu et al., 2024. "KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache." arXiv:2402.02750.
- Frantar and Alistarh, 2022. "Optimal Brain Compression." arXiv:2208.11580.
- Bondarenko et al., 2021. "Understanding and Overcoming the Challenges of Efficient Transformer Quantization." EMNLP 2021. arXiv:2109.12948.
- NVIDIA TransformerEngine: github.com/NVIDIA/TransformerEngine
Ready to operationalize what you read?
Strongly.AI's forward deployed engineers have shipped every layer of this stack in production. If you want help going from "we read the papers" to "we serve this at scale", let's talk.
Schedule A Demo